Содержание
- Введение 1
- Обзор литературы 2
- Теоретические основы 3
- Методология исследования 4
- Сбор и подготовка данных 5
- Расчет информационного веса 6
- Сравнительный анализ 7
- Обсуждение результатов 8
- Заключение 9
- Список литературы 10
Данный исследовательский проект посвящен детальному анализу и сравнительной оценке информационного веса символов, используемых в различных алфавитных системах, включая русский, английский и другие распространенные алфавиты. Проект ставит своей целью количественное определение и сопоставление объемов информации, которые несет каждая буква. Ожидается, что результаты исследования позволят выявить закономерности в плотности информации, присущей разным языкам, и их влияние на эффективность кодирования и обработки данных. Будут использованы методы математической статистики и теории информации для объективного анализа. Проект направлен на углубленное понимание фундаментальных принципов представления информации и их вариативности в зависимости от лингвистической структуры. Полученные данные могут найти применение в криптографии, лингвистике, компьютерных науках и разработке алгоритмов сжатия данных.
Идея проекта заключается в количественной оценке информационного содержания каждого символа в русском, английском и других алфавитах. На основе полученных данных будет проведен сравнительный анализ плотности информации в разных языках.
Продуктом проекта является сравнительный анализ информационного веса символов алфавитов, представленный в виде отчета с графиками и таблицами. Отчет наглядно демонстрирует различия в информативности алфавитов и может служить основой для дальнейших исследований.
Традиционные методы анализа текста часто игнорируют различное информационное содержание отдельных символов, что может приводить к неэффективному кодированию и алгоритмам обработки. Отсутствие стандартизированных метрик для сравнения информационного веса символов в разных языках затрудняет кросс-языковые исследования.
Актуальность проекта обусловлена растущим объемом информации и необходимостью разработки более эффективных методов её обработки и хранения. Понимание информационного веса символов напрямую влияет на оптимизацию алгоритмов, используемых в компьютерной лингвистике, криптографии и системах машинного перевода.
Целью проекта является определение и сравнение информационного веса символов русского, английского и других алфавитов. Результаты послужат основой для разработки более точных моделей анализа текста и эффективных методов его кодирования.
Целевой аудиторией проекта являются студенты и исследователи в области информатики, лингвистики, математики и смежных дисциплин. Также проект будет интересен специалистам, занимающимся разработкой алгоритмов обработки естественного языка и криптографией.
Для реализации проекта потребуются персональные компьютеры с доступом к интернету, специализированное программное обеспечение для статистического анализа и обработки данных (например, Python с библиотеками NumPy, SciPy, Pandas), а также доступ к корпусам текстов на различных языках.
Осуществляет общее стратегическое планирование, консультирует по теоретическим аспектам, контролирует ход исследования и соответствие академическим стандартам, оказывает методологическую поддержку.
Отвечает за сбор, очистку и предварительную обработку данных, применение статистических методов и алгоритмов для расчета информационного веса символов, проводит анализ и интерпретацию полученных результатов.
Предоставляет экспертную оценку лингвистической природы символов и их закономерностей в текстах, участвует в интерпретации результатов с точки зрения языковых особенностей.
Отвечает за разработку скриптов и программного обеспечения для автоматизации сбора данных, расчетов и визуализации результатов, обеспечивает техническую реализацию алгоритмов.
Выполнил: ФИО
Руководитель: ФИО
В этом разделе будет представлен обзор существующих исследований по теории информации, статистическому анализу текстов и сравнительной лингвистике. Будут рассмотрены работы, связанные с энтропией, информационным содержанием символов и методами анализа языков. Оценит научную новизну предлагаемой работы.
Здесь будут детально рассмотрены теоретические концепции, лежащие в основе проекта, такие как теория информации, понятие энтропии Шеннона и методы ее расчета применительно к символам языка. Будут объяснены принципы количественной оценки информационного веса, что является фундаментом для дальнейших расчетов. Эта часть обеспечивает понимание методологии.
В данном разделе будет описан план исследования, включающий в себя выбор алфавитов для анализа, источники данных (корпусы текстов), а также конкретные алгоритмы и методы, которые будут применяться для расчета информационного веса символов. Будет подробно описан процесс сбора и обработки данных, а также инструментарий.
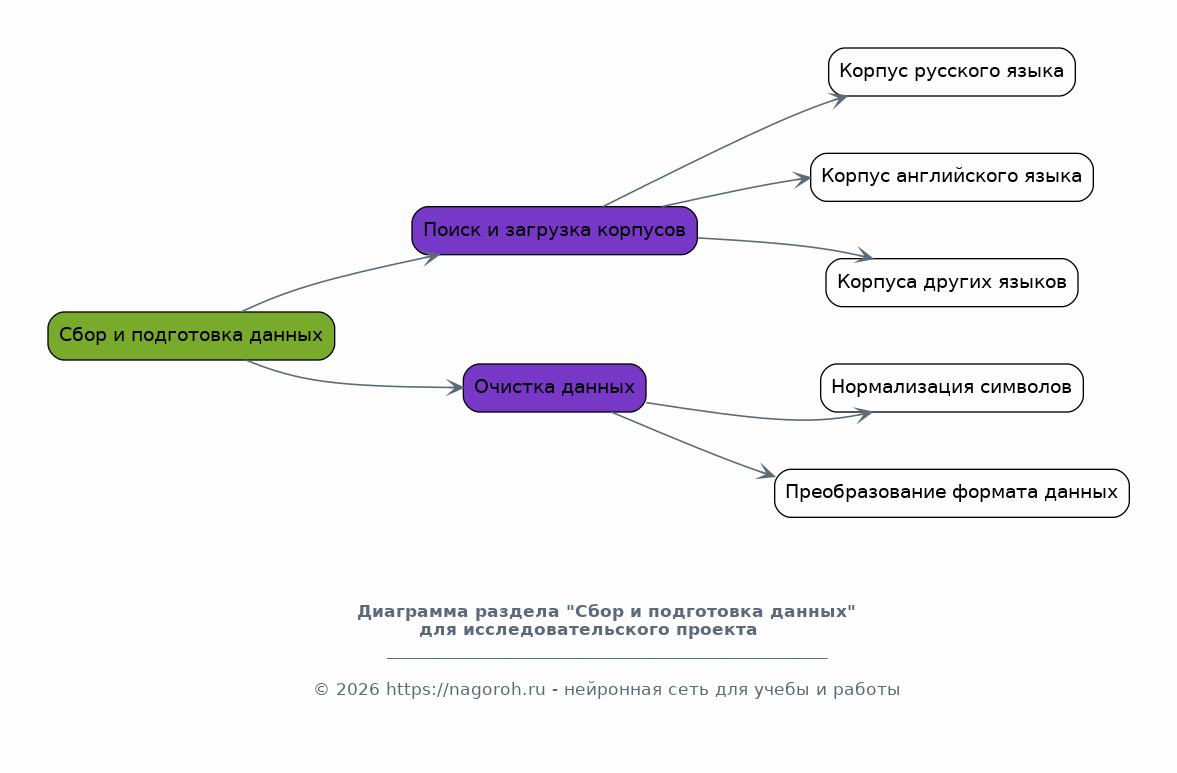
Этот пункт фокусируется на практической стороне сбора данных: поиск и загрузка корпусов текстов на русском, английском и других языках. Будут описаны процедуры очистки данных, нормализации символов и подготовки их к дальнейшему статистическому анализу. Обеспечивает релевантность и чистоту эмпирических данных.
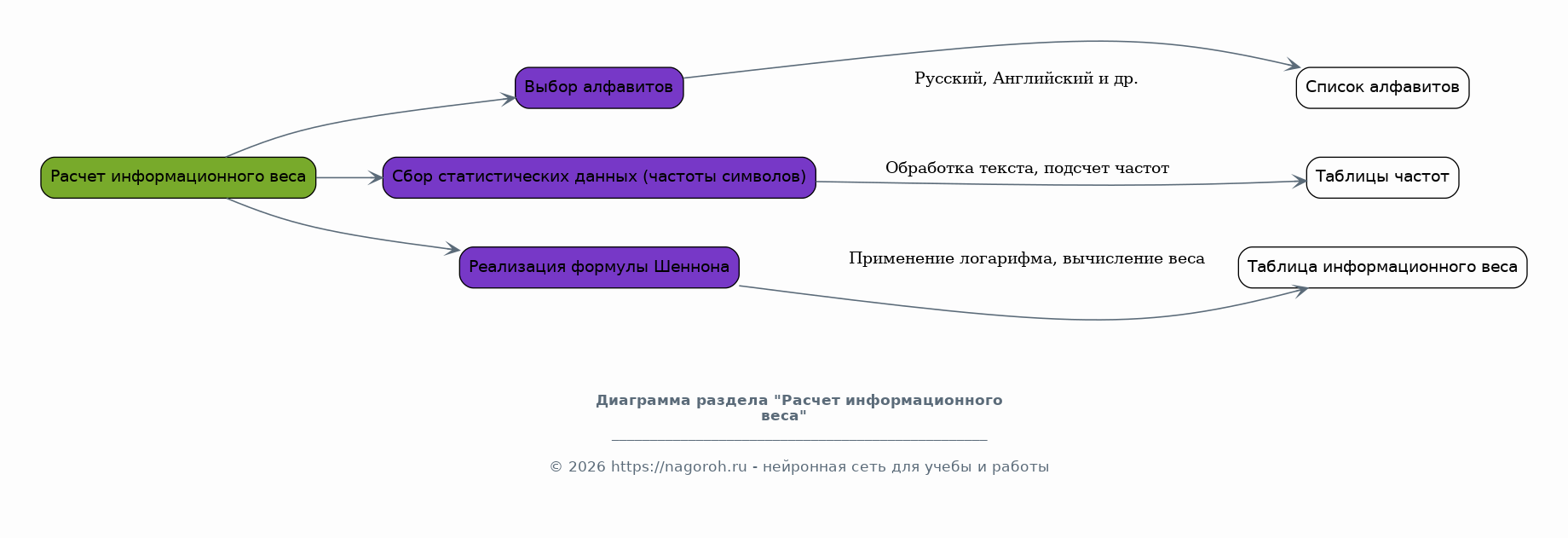
Здесь будет осуществлен практический расчет информационного веса для каждого символа в выбранных алфавитах с использованием разработанной методологии и программного обеспечения. Будут представлены промежуточные результаты расчетов, демонстрирующие примененные формулы и алгоритмы. Эта часть является ядром практической работы.
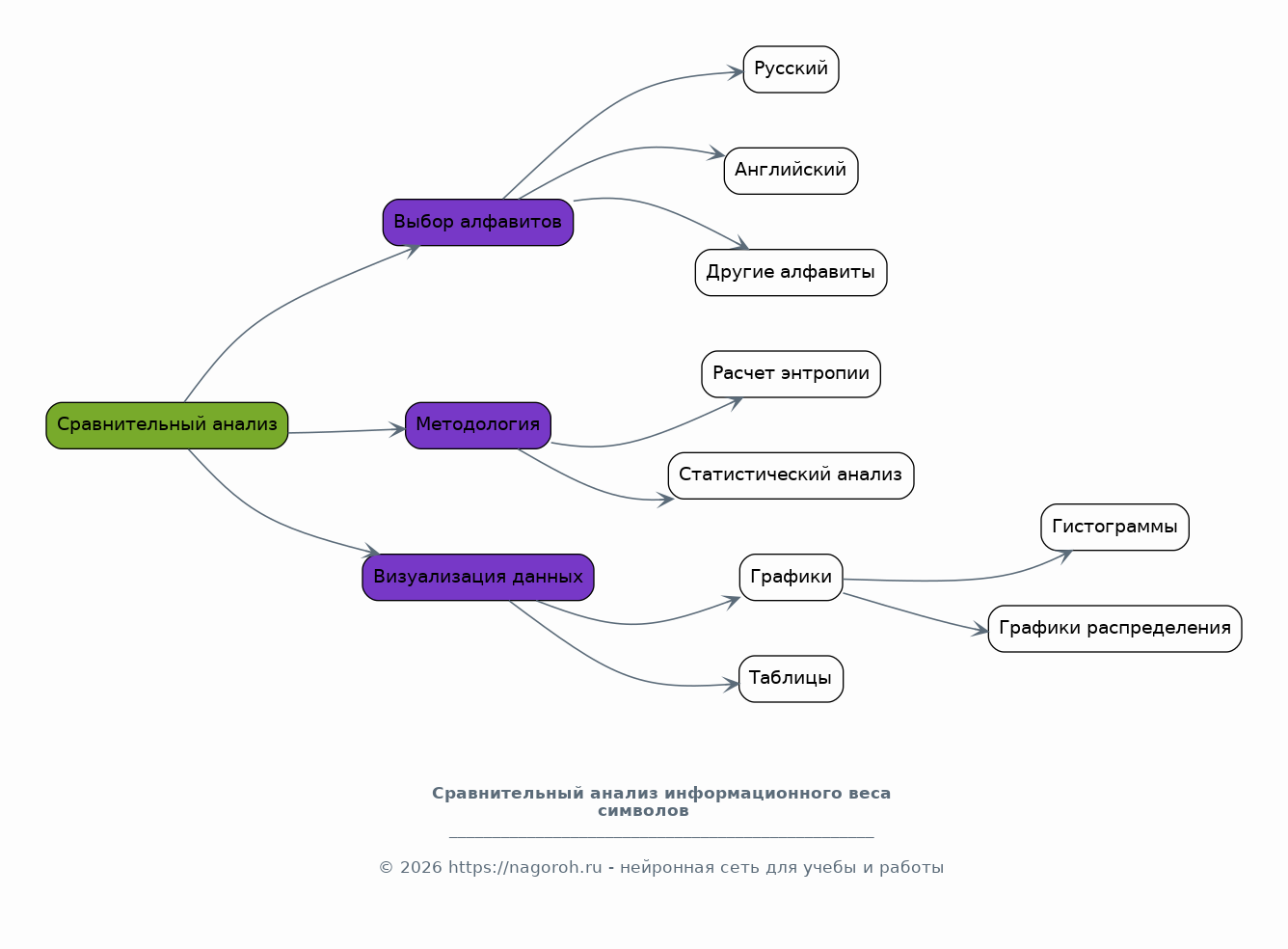
В этом разделе будет проведен сравнительный анализ информационного веса символов между различными алфавитами. Отобразит полученные данные в виде наглядных графиков и таблиц, иллюстрирующих различия в плотности информации. Будут выявлены основные тенденции и паттерны.
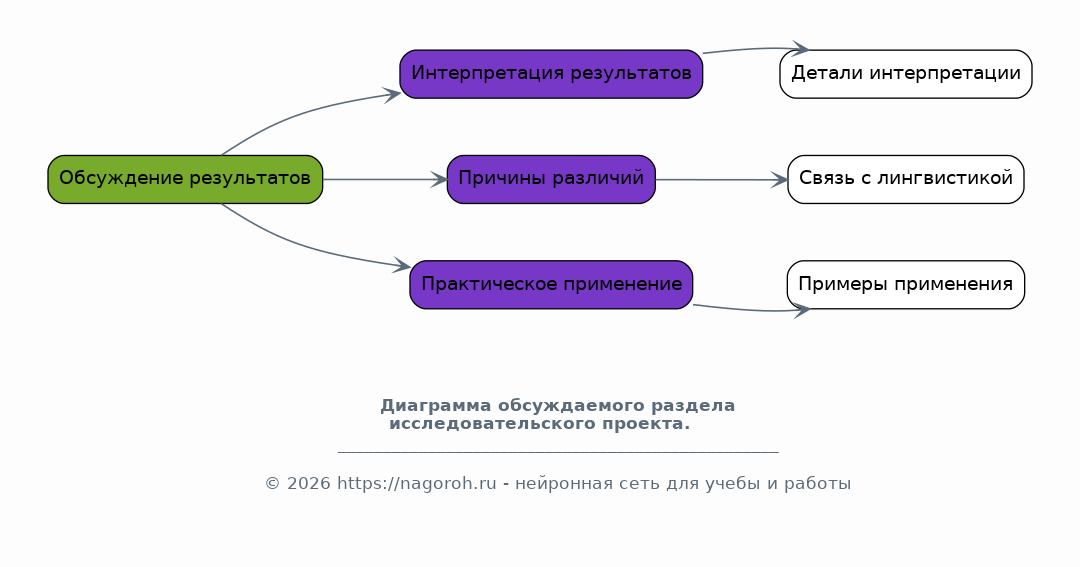
Здесь будет проведена интерпретация полученных в ходе сравнительного анализа результатов. Будут обсуждаться возможные причины выявленных различий в информационном весе символов, их связь с лингвистическими особенностями языков и потенциальное практическое применение. Сделаны предположения о закономерностях.
В данном разделе будут подведены итоги всего исследования. Будут кратко суммированы основные результаты, достигнутые цели и сформулированы рекомендации для дальнейших исследований. Здесь же будут отмечены ограничения работы и ее вклад в науку.